Big Data: A Comprehensive Introduction
1. Understanding Big Data
Big Data refers to a collection of data sets so vast and complex that traditional data processing applications are inadequate to deal with them. It encompasses immense quantities of data, necessitates advanced data management capabilities, and often involves social media analytics and real-time data processing. Big Data analytics is the process of examining these large and diverse data sets to uncover hidden patterns, unknown correlations, market trends, customer preferences, and other useful information.
The digital landscape is flooded with heterogeneous data, including documents, videos, and audio files. What defines Big Data is not just its sheer volume, often measured in terabytes or petabytes, but also its velocity (speed of generation and processing) and variety (diversity of data types). These "3 Vs" are foundational to understanding Big Data.
However, dealing with Big Data presents significant challenges: capturing, analyzing, storing, searching, sharing, visualizing, and transferring these massive datasets, alongside critical concerns like data privacy. Traditional SQL queries and relational database management systems (RDBMS) are insufficient for managing and processing Big Data. Consequently, a wide variety of scalable database tools and techniques have evolved. Hadoop, an open-source distributed data processing framework, stands out as a prominent and widely adopted solution. Non-relational databases, often referred to as NoSQL databases, such as MongoDB, also play a crucial role.
2. The Scale of Big Data
Our technological evolution underscores the growth of data. We've transitioned from landline phones to smartphones and from floppy drives to hard disks, driven by the ever-increasing demand for storage capacity and transfer speed. Floppy drives, with their limited capacity, are clearly inadequate for the data volumes we handle today. Modern solutions, like cloud storage, now allow us to store terabytes of data effortlessly, unburdened by local size constraints.
Several key drivers contribute to this exponential data generation:
- Internet of Things (IoT): IoT connects physical devices to the internet, imbuing them with intelligence. Smart air conditioners, for instance, continuously monitor room and external temperatures to optimize climate control. Imagine the vast amounts of data generated annually by thousands of such devices in homes worldwide. IoT is undoubtedly a major contributor to Big Data.
- Social Media: Platforms like Facebook, Twitter, and Instagram generate petabytes of data daily through user interactions, posts, and media uploads.
- Sensors and Wearables: Devices in smart cities, industrial machinery, and personal health trackers continuously stream data.
- Digital Transactions: Every online purchase, banking transaction, or web search creates data.
Beyond the sheer volume and velocity, the lack of a proper format or structure in many of these data sets (the "variety" aspect) presents a significant challenge for traditional processing methods.
3. Big Data with the Hadoop Framework
The genesis of Hadoop is rooted in the ambition of Mike Cafarella and Doug Cutting to build a search engine capable of indexing a billion web pages. Their initial estimations revealed a prohibitive cost: approximately half a million dollars for hardware, with a $30,000 monthly running cost. Furthermore, they quickly realized their existing architecture wouldn't scale to handle billions of web pages.
Their breakthrough came in 2003 with the publication of a paper describing Google's Distributed File System (GFS), which was already in production at Google. GFS provided the solution they needed for storing the extremely large files generated during web crawling and indexing. In 2004, Google released another pivotal paper introducing MapReduce. These two papers collectively laid the foundation for the framework known as Hadoop. Doug Cutting famously remarked on Google's foresight: "Google is living a few years in the future and sending the rest of us messages."
4. Big Data and Hadoop: A Restaurant Analogy
To better understand the problems associated with Big Data and how Hadoop provides a solution, let's consider a restaurant analogy.
Bob owns a small restaurant. Initially, he received about two orders per hour, and a single chef with one food shelf was sufficient to manage operations.

Figure 1: Traditional Scenario - A single chef with one food shelf and steady orders.
This scenario parallels traditional data processing, where data generation was steady, and traditional systems like RDBMS were capable of handling it. Here, the data storage can be related to the restaurant's food shelf, and the traditional processing unit to the chef.
After a few months, Bob decided to expand, introducing online orders and adding more cuisines. This expansion dramatically increased the order rate to an alarming 10 orders per hour, overwhelming the single chef. Bob began seeking a solution to this processing bottleneck.

Figure 2: Big Data Scenario - Single chef overwhelmed by increased orders.
Similarly, in the Big Data era, data generation exploded due to drivers like social media and smartphones. Traditional systems, much like Bob's single cook, proved inefficient in coping with this sudden surge. A different strategic solution was urgently needed.
Bob's initial solution was to hire four more chefs to handle the increased order volume. While this improved processing capacity, it introduced a new problem: the single, shared food shelf became a bottleneck, limiting the overall efficiency.
Figure 3: Multiple chefs sharing a single food shelf, showing bottleneck.
Analogously, to process huge datasets, multiple processing units were employed for parallel data processing. However, this didn't entirely resolve the issue because the centralized storage unit became the bottleneck. The performance of the entire system became dependent on the central storage unit, creating a single point of failure. If the central storage failed, the whole system would be compromised. Thus, there was still a need to address this single point of failure and improve overall efficiency.
5. Solution to the Restaurant Problem
Bob devised a more efficient solution. He restructured his kitchen, dividing his chefs into two hierarchies: junior chefs and a head chef. He assigned each junior chef their own dedicated food shelf. For a dish like Meat Sauce, for example, one junior chef would prepare the meat, and another would prepare the sauce. These pre-prepared components would then be transferred to the head chef, who would combine them to prepare the final Meat Sauce dish for delivery.

Figure 4: Bob's new restaurant hierarchy with distributed food shelves.
6. Hadoop in the Restaurant Analogy
Hadoop functions in a remarkably similar fashion to Bob's optimized restaurant. Just as the food shelves are distributed in Bob's restaurant, data in Hadoop is stored in a distributed fashion with replications to provide fault tolerance and prevent a single point of failure. For parallel processing, data is first processed by "slave" nodes where it is stored, generating intermediate results. These intermediate results are then merged by a "master" node to produce the final outcome.
This analogy helps to crystallize why Big Data presents a significant problem and how Hadoop addresses it by tackling three major challenges:
- Storing Colossal Amounts of Data: Traditional systems cannot store vast amounts of data due to their limited, centralized storage. As data grows tremendously, a distributed storage solution is essential.
- Storing Heterogeneous Data: Beyond volume, data comes in various formats—unstructured, semi-structured, and structured. A robust system must accommodate all these diverse types of data generated from various sources.
- Processing Speed: The time required to process these enormous datasets with traditional methods is exceedingly high.
To overcome these storage and processing challenges, Hadoop introduced two core components: HDFS (Hadoop Distributed File System) for storage, and YARN (Yet Another Resource Negotiator) for processing. HDFS provides scalable, distributed data storage, while YARN drastically reduces processing time by enabling distributed and parallel computation.
7. What is Hadoop?
Hadoop is an open-source software framework designed for storing and processing Big Data in a distributed manner across large clusters of commodity hardware. Licensed under the Apache v2 license, Hadoop was developed by Doug Cutting and Michael J. Cafarella, drawing heavily from Google's foundational papers on MapReduce. Written primarily in Java, Hadoop is recognized as one of the highest-level Apache projects.
Let's delve into how Hadoop provides solutions to the Big Data problems discussed earlier.
8. Hadoop-as-a-Solution
- Solving the Storage Problem (HDFS):
HDFS provides a distributed mechanism for storing Big Data. Data is divided into blocks (e.g., 128 MB) and stored across multiple DataNodes. For example, a 512 MB file would be split into four 128 MB blocks and distributed across different DataNodes. Crucially, these data blocks are replicated across various DataNodes to ensure fault tolerance. If one DataNode fails, the data remains accessible from its replicas.
Hadoop employs horizontal scaling rather than vertical scaling. This means you can expand your HDFS cluster by adding new, inexpensive commodity nodes on the fly, instead of upgrading the hardware stack within existing nodes. This approach offers significant cost-effectiveness and flexibility.
- Solving the Variety Problem (HDFS Flexibility):
HDFS is exceptionally versatile in handling data variety. It can store all kinds of data—structured, semi-structured, or unstructured—without imposing a pre-dumping schema validation. This "schema-on-read" approach, coupled with its "write once, read many" model, allows you to ingest any type of data and then analyze it multiple times to extract insights. - Solving the Processing Speed Problem (YARN & Data Locality):
Hadoop addresses the processing speed challenge by adhering to the principle of "moving computation to data" rather than "moving data to computation." This means that instead of transferring massive datasets from various nodes to a single master node for processing, the processing logic (or computation unit) is sent directly to the nodes where the data is stored. Each node then processes its local portion of the data in parallel. Finally, all the intermediary outputs generated by each node are merged by the master node, and the final response is sent back to the client. This dramatically reduces network traffic and processing time.
9. Hadoop Features
Hadoop's core characteristics make it an ideal solution for Big Data challenges:
- Reliability: Hadoop infrastructure boasts built-in fault tolerance. When machines operate in a cluster, if one fails, another seamlessly takes over its responsibilities. This inherent reliability ensures continuous operation.
- Economical: Hadoop leverages commodity hardware (standard PCs, servers, etc.), significantly reducing hardware costs. For instance, a small Hadoop cluster can operate effectively with nodes featuring modest RAM (8-16 GB) and hard disk capacities (5-10 TB) and standard processors. This contrasts sharply with proprietary, high-end hardware solutions (e.g., hardware-based RAID with Oracle), which could cost five times more. Furthermore, as an open-source software, Hadoop incurs no licensing fees, further minimizing the total cost of ownership and maintenance.
- Scalability: Hadoop inherently integrates seamlessly with cloud-based services. This allows for rapid horizontal scaling; you can procure and add more hardware to expand your cluster setup within minutes as needed, without disrupting ongoing operations.
- Flexibility: Hadoop's flexibility is paramount. It can store and process virtually any kind of data—structured, semi-structured, or unstructured—originating from diverse sources.
These four characteristics collectively position Hadoop as a leading framework for addressing complex Big Data challenges.
10. Hadoop Core Components
While a Hadoop cluster can incorporate numerous services, two are absolutely mandatory for its setup and operation: HDFS (storage) and YARN (processing). HDFS, the Hadoop Distributed File System, provides scalable and distributed storage, while YARN manages and processes data stored in HDFS in a distributed and parallel fashion.
10.1. HDFS
HDFS comprises two main components: the NameNode and DataNodes.
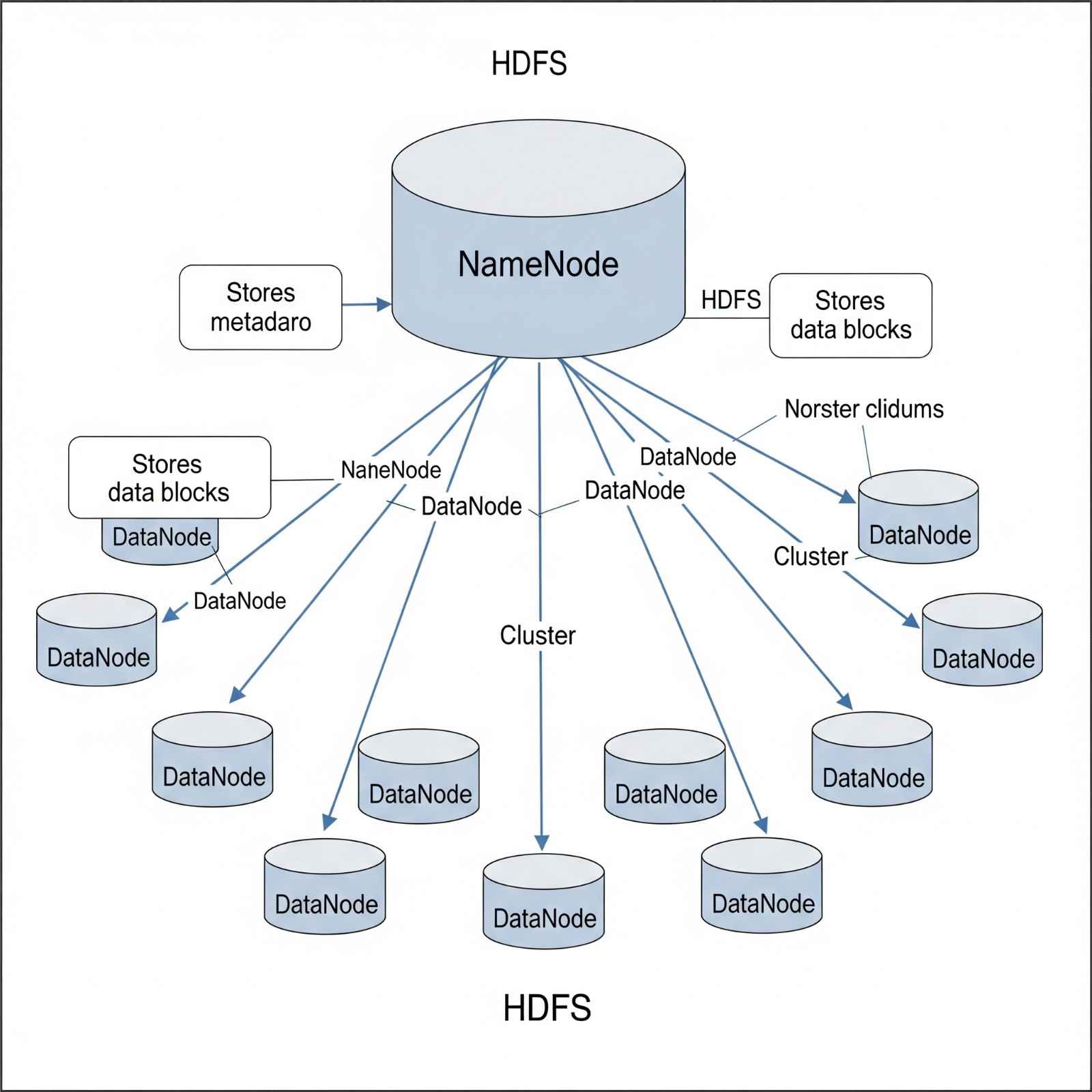
Figure 5: HDFS Architecture showing NameNode and DataNodes.
- NameNode:
- Acts as the master daemon, maintaining and managing the DataNodes (slave nodes).
- Stores the metadata for all blocks in the cluster, including block locations, file sizes, permissions, and file system hierarchy.
- Records every change to the file system metadata (e.g., file deletions are immediately logged in the EditLog).
- Regularly receives Heartbeat signals and block reports from all DataNodes to confirm their live status and health.
- Maintains a comprehensive record of all HDFS blocks and their corresponding DataNodes.
- Supports high availability and federation features (to be discussed in detail in HDFS architecture specifics).
- DataNode:
- Functions as the slave daemon, running on each slave machine in the cluster.
- Responsible for storing the actual data blocks.
- Serves read and write requests from clients.
- Manages the creation, deletion, and replication of data blocks based on the decisions from the NameNode.
- Periodically sends Heartbeat signals to the NameNode (default frequency: 3 seconds) to report on the overall health of HDFS.
This summarizes the core functionalities of HDFS. Let's now move to YARN, the second fundamental unit of Hadoop.
10.2. YARN
YARN is composed of two primary components: the ResourceManager and NodeManager.
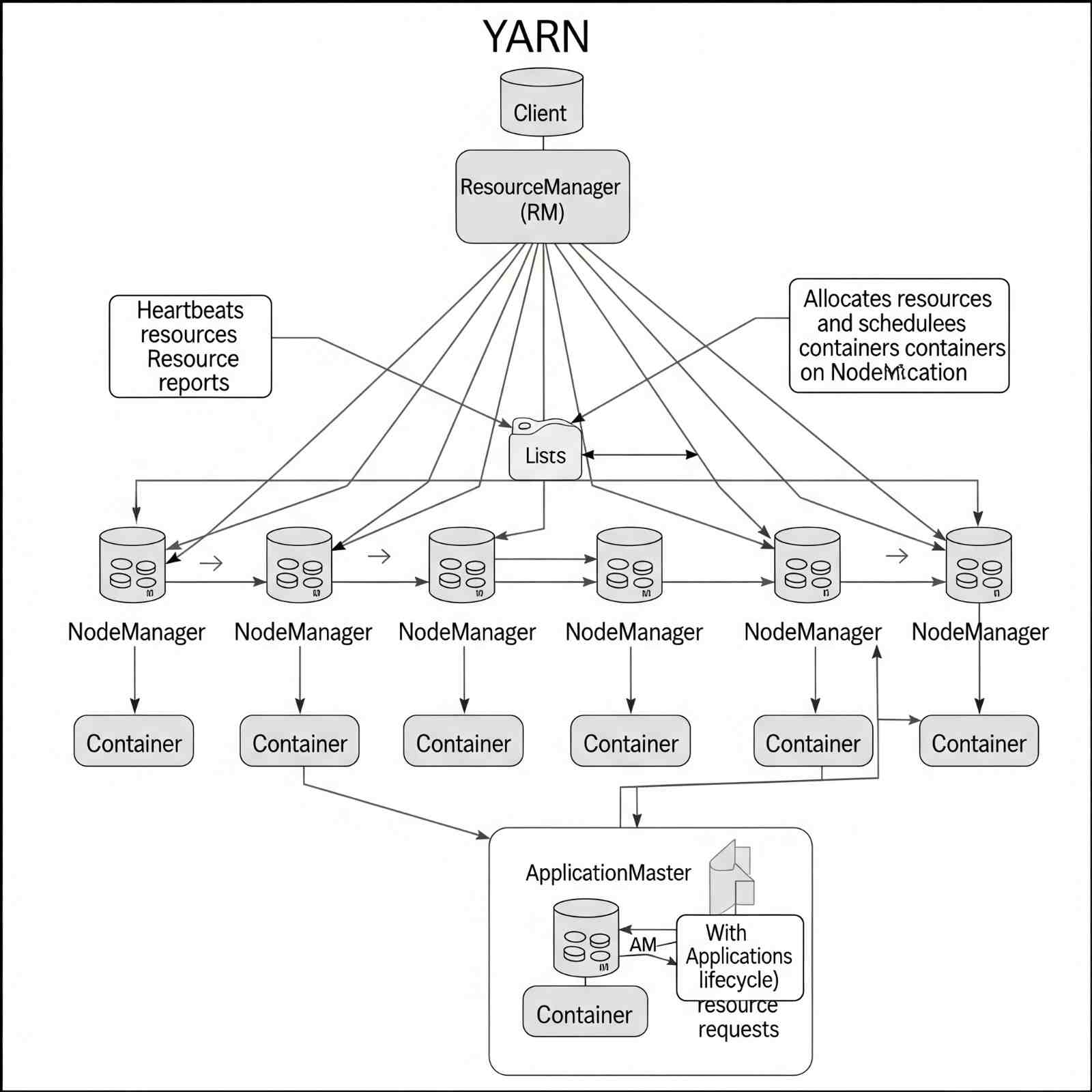
Figure 6: YARN Architecture showing ResourceManager and NodeManager.
- ResourceManager:
- A cluster-level component, running on the master machine.
- Manages resources across the entire cluster and schedules applications running on top of YARN.
- Consists of two sub-components:
- Scheduler: Responsible for allocating resources to various running applications.
- ApplicationManager: Handles job submissions and negotiates the initial container for executing an application.
- Tracks Heartbeat signals from NodeManagers.
- NodeManager:
- A node-level component, running on each slave machine.
- Responsible for managing containers (isolated environments for application execution) and monitoring resource utilization in each container.
- Also keeps track of node health and log management.
- Continuously communicates with the ResourceManager to remain up-to-date.
11. The Hadoop Ecosystem
It's crucial to understand that Hadoop is neither a programming language nor a single service; it is a platform or framework designed to solve Big Data problems. It can be considered a suite encompassing a multitude of services for ingesting, storing, and analyzing massive datasets, alongside tools for configuration management.
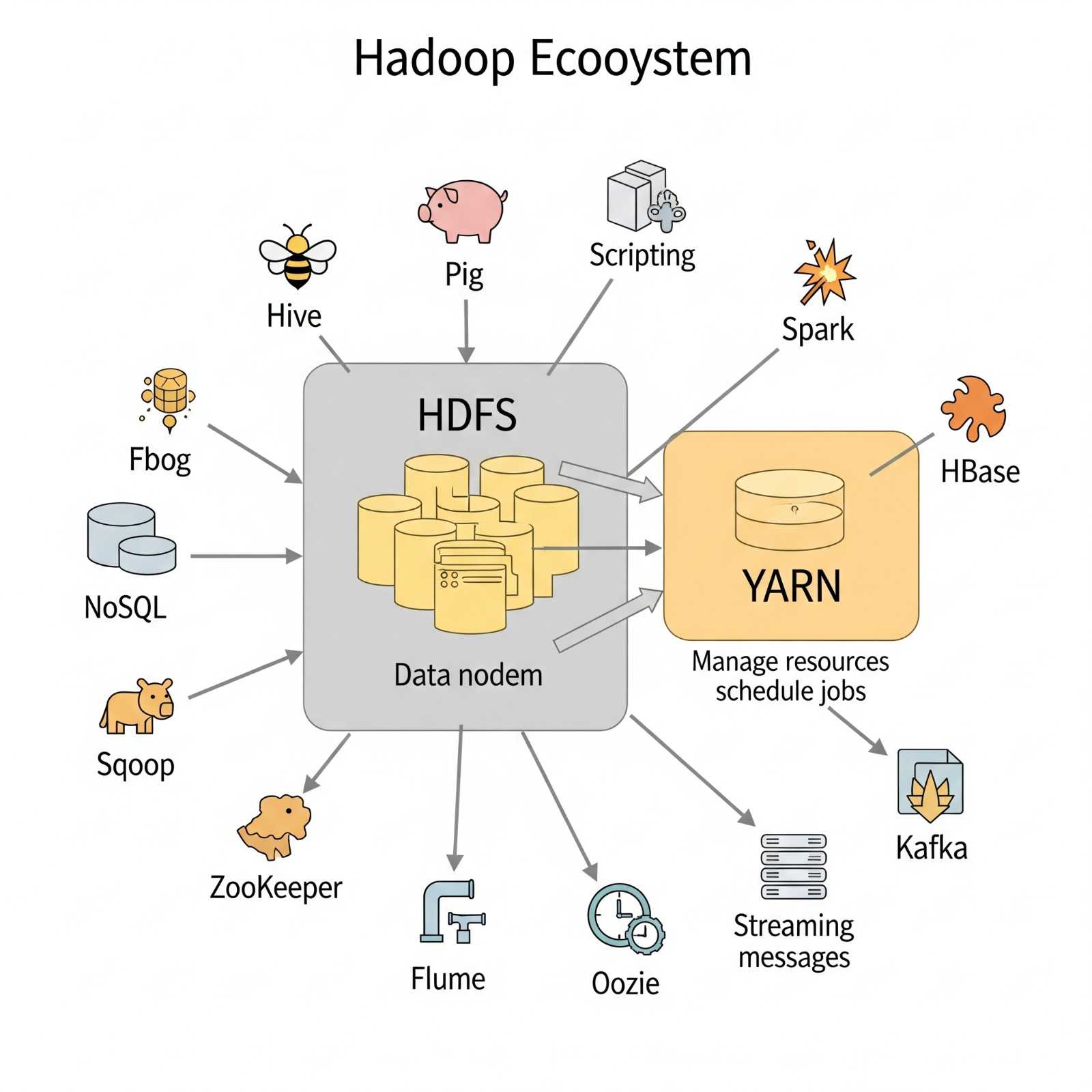
Figure 7: Hadoop Ecosystem Diagram with various components like Hive, Pig, Spark, HBase, etc.
This ecosystem includes various tools that build upon HDFS and YARN, such as Hive (for SQL-like queries on HDFS data), Pig (for high-level data flow programs), HBase (a NoSQL database), Spark (for fast data processing), and many more, each addressing specific Big Data needs within the larger Hadoop framework.